For supervised machine learning tasks, AutoML can significantly speed up your time to deployment and tighten the feedback loop for feature experimentation. To make sure the tools perform reasonably well, we test H2O AutoML against a popular benchmark of commonly used machine learning algorithms using both a single virtual machine and a cluster of four such machines running Apache Spark on AWS ElasticMapReduce (EMR). Once you know how to use AutoML, you might want to think about where to leverage it so as to provide the most value. At the end of the post, we’ll give you some insight into how we think about these tools at IKASI. For now, here’s how to get up and running.
Automatic Machine Learning (AutoML) tools allow you to benefit from the predictive power of stacked model ensembles with just a table of data and the name of the column you want to predict. With H2O.ai Sparkling Water, these tools have reached the point where they can handle building one-off models on any amount of data. You can use AutoML to:
- Start with a good model as a baseline
- See how different kinds of models perform on your dataset
- Avoid common pitfalls of machine learning
How to: Single Machine
See Appendix: How to provision a VM in AWS EC2, or ssh into an existing VM running linux. When you have access to a VM, follow these instructions to install H2O with python:
How to: Cluster
Create an EMR cluster using the AWS Management Console to make sure the default roles are created. Once that’s done you can terminate it. Add ssh access for your ip address to the inbound rules for the EMR master security group in AWS.
This script will create a cluster, or add steps to an existing cluster. Edit run_test_emr.py before running it to set up your preferences and AWS account-specific information at the top of the file. It adds three steps for each modeling job, although the first step could be run as a bootstrap action instead once the modeling code is stable.
- Copy the modeling code (model_script.py) from S3 to the EMR cluster driver
- Use spark-submit to run the main step
- a. Use
spark.yarn.maxAppAttempts=1to disable retries - b. Use ‘cluster’ deploy mode and ‘yarn’ master
- c. model_script.py is in python2
- a. Use
- Copy the model results from the cluster’s hadoop filesystem to S3
Example Data
| Month | DayofMonth | DayOfWeek | DepTime | UniqueCarrier | Origin | Dest | Distance | dep_delayed_15min |
| c-8 | c-21 | c-7 | 1934 | >AA | ATL | DFW | 732 | N |
| c-4 | c-20 | c-3 | 1548 | US | PIT | MCO | 834 | N |
| c-9 | c-2 | c-5 | 1422 | XE | RDU | CLE | 416 | N |
| c-11 | c-25 | c-6 | 1015 | OO | DEN | MEM | 872 | N |
| c-10 | c-7 | c-6 | 1828 | WN | MDW | OMA | 423 | Y |
Results
We trained H2O AutoML on a single virtual machine (r4.8xlarge) using ten million rows of data from the szilard benchmark. The data consists of eight input columns (six categorical, two numeric) and one output column (dep_delayed_15min). The categorical columns are of low cardinality, and there is no missing data. With a requested stopping time of six thousand seconds (one hour and forty minutes), H2O AutoML achieved an average Area Under the Curve (AUC) of 79.85 over three runs with its best-of-family ensemble. For comparison, on the benchmark the best linear model achieved an AUC of 71.1, the best Random Forest (RF), 77.8, and the best Gradient Boosting Machine (GBM), 78.7 in a similar amount of time.
On a cluster of four machines in Amazon Elastic MapReduce (EMR), the Sparkling Water version managed an AUC of 78.01, also averaged over three runs. When given four hours, Sparkling Water was able to achieve an AUC of 80.9 in a single run. The best result in the benchmark was an AUC of 81.2, achieved by training a GBM for more than nine hours. This is the power of stacked ensembles, models that combine the predictions of disparate machine learning models to do better than any one model by itself.
If your data has fewer than one hundred million rows, we’d recommend using single-machine H2O AutoML on a memory-optimized EC2 instance. Otherwise, or if you have existing Spark infrastructure, the Sparkling Water version still performs quite well, and there are other options available to those with more machine learning expertise. When using Spark, you may need to specify the data types manually. For the purposes of the benchmark, we had to convert string columns to enums using asfactor.
Single Machine (r4.8xlarge) – 32 virtual CPUs, 244 GiB memory, $2.128 per hour
max_runtime_secs: 6000 seconds (1 hr 40 mins)
actual runtime: 6946.8 seconds, 6859.2 seconds, 6868.7 seconds
Leaderboard-1, Leaderboard-2, Leaderboard-3
Best of Family AUC: 0.800351, 0.796376, 0.798908
Best of Family AUC sample mean: 0.7985, sample variance: 4.049e-06
Cluster – four r4.8xlarge workers, one m4.4xlarge master
max_runtime_secs: 6000 (1 hour 40 mins)
actual runtime: 6362.7 seconds, 6316.5 seconds. 6439.1 seconds
step runtime: 1 hour 51 min, 1 hour 50 min, 1 hour 52 min
Leaderboard-1, Leaderboard-2, Leaderboard-3
Best of Family AUC: 0.77937, 0.780583, 0.780254
Best of Family AUC sample mean: 0.7801, sample variance: 3.935e-07
Leaderboard-4
max_runtime_secs: 12000 (3 hour 20 mins)
>actual runtime: 12646.8 seconds
step runtime: 3 hours 36 min
Best of Family AUC: 0.808793
Without access to the test set, we would have chosen StackedEnsemble_BestOfFamily or StackedEnsemble_AllModels, but sometimes they do slightly worse on the test set when compared to a particular GBM (Gradient Boosting Machine) or DRF (Distributed Random Forest). See this video by H2O for more on their implementations of GBMs and DRFs. The best-of-family ensemble model would include only the best models of each kind in the final ensemble. Extremely Random Trees (XRT), Neural Networks (DeepLearning), and Generalized Linear Models (GLM) are more examples of the kinds of model generated by H2O AutoML.
Conclusion
Until now, various implementations of the Random Forest algorithm have been the most user-friendly machine learning options. With the release of H2O AutoML, this is no longer the case. From an engineering standpoint, it is a huge advantage to be able to provide a training set, a test set (optional), and a column to predict, with no need to set any parameter other than how long you want the job to take. In addition, the output is considerably more helpful as a baseline than a linear model or any model alone. After feature engineering, machine learning is in practice about finding the best algorithm for the job. You need to test a panel of algorithms after each change to the input data, and H2O AutoML makes it possible at any scale.
At IKASI, we use AutoML as a sanity check, not a cure-all. It can’t find features for you, but it can tell you which ones are useful to your model. Don’t ignore the human context: define your objectives around your business, not just metrics like AUC. Finally, AutoML is a great way to avoid the pitfalls of Machine Learning. Data leakage for example, is commonly found when your model achieves perfect results on the test set. As usual, if it looks too good to be true, it probably is.
Appendix
Create a keypair (on a mac, using ssh-keygen -t rsa), perhaps choose ~/.ssh/emr_test_rsa for your private key location, and ~/.ssh/emr_test_rsa.pub for your public key location. Then use aws ec2 import-key-pair --key-name emr_test_rsa --public-key-material file://~/.ssh/emr_test_rsa.pub to import your key pair.
Create a launch template, replacing “subnet-1234a56b” with your own subnet:
1 2 3 |
export MY_SUBNET="subnet-1234a56b"; aws s3 cp s3://emr-h2o-automl-benchmark/launch-template-single-new.json - | sed "s/MY_SUBNET/$MY_SUBNET/" > launch_template.json aws ec2 create-launch-template --launch-template-name automl_test --launch-template-data "$(cat launch_template.json | tr -d '[:space:]')" |
Create an EC2 instance in AWS by choosing “Launch instance from template” from the console.
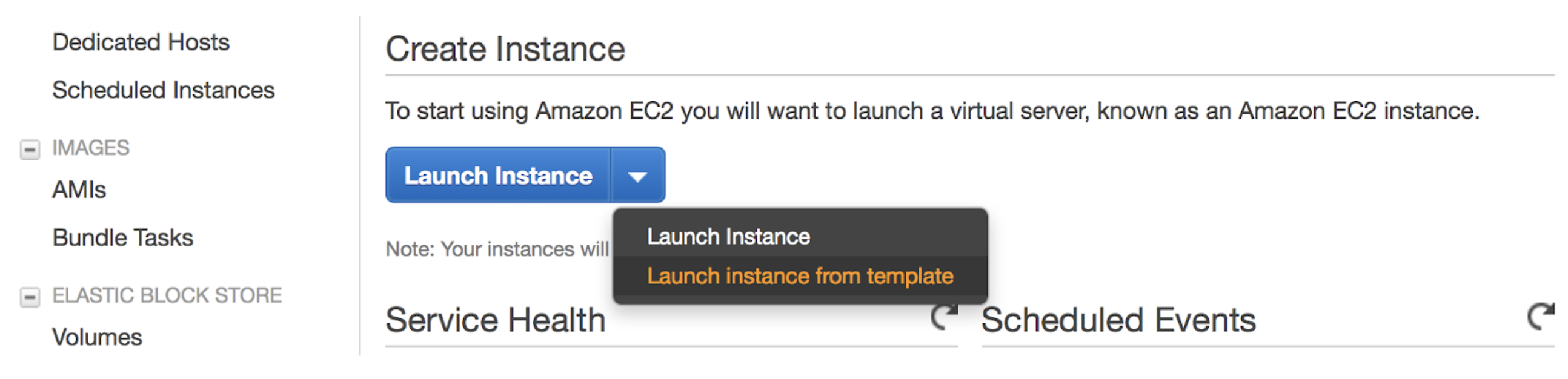
Choose the first version of the template, then scroll down and launch the instance. Once your instance launches, you can add your IP address to the security group Inbound Rules and use the public IP to ssh to your VM and install H2O. Select the instance in your console and you’ll find the public IP. Click the default security group to edit the inbound rules and add your IP address.
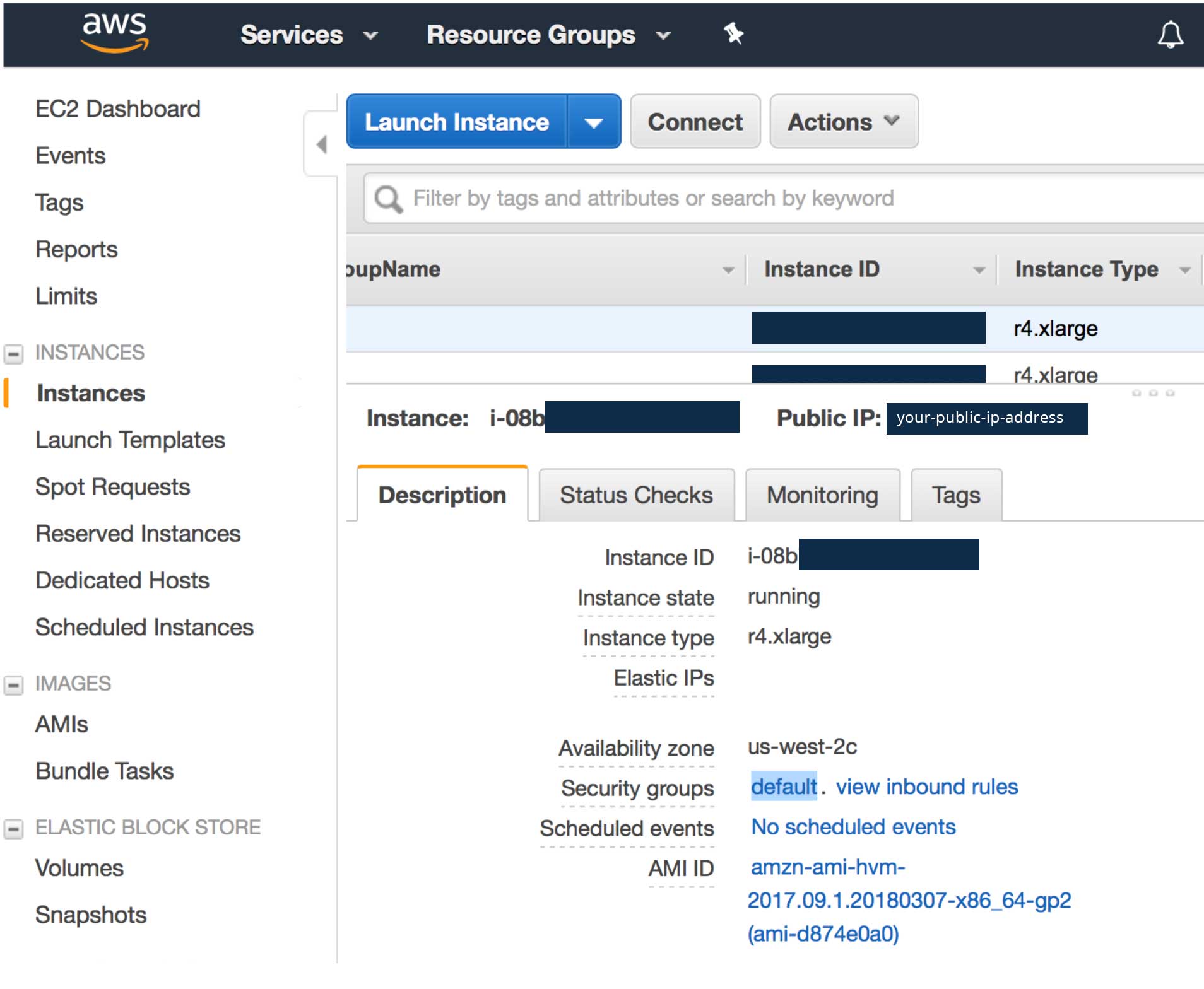
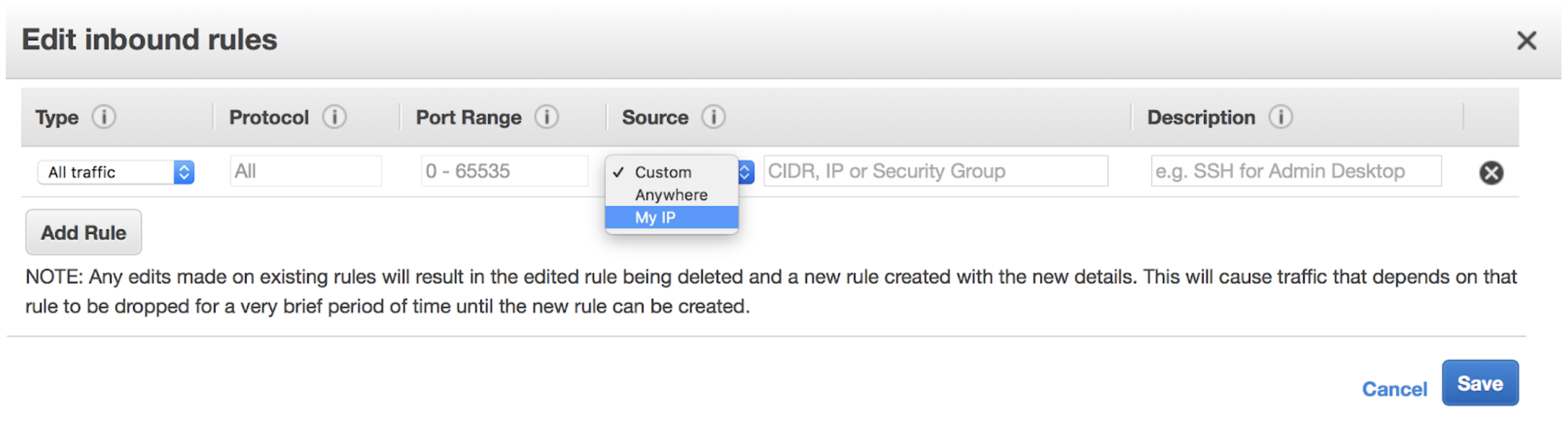
Next ssh to the VM using ssh -i "~/.ssh/emr_test_rsa" ec2-user@<your-public-ip-address> and replace the ip address with the one for your VM.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
{
"JobFlowRole": "EMR_EC2_DefaultRole",
"LogUri": "${EMR_LOG_URI}",
"Instances": {
"EmrManagedMasterSecurityGroup": "${EMR_MASTER_SG}",
"KeepJobFlowAliveWhenNoSteps": true,
"EmrManagedSlaveSecurityGroup": "${EMR_WORKER_SG}",
"InstanceGroups": [
{
"InstanceType": "${EMR_MASTER_INSTANCE_COUNT}",
"InstanceType": "${EMR_MASTER_INSTANCE_TYPE}",
"Market": "ON_DEMAND",
"InstanceRole": "MASTER",
"Name": "master_instance_group"
},
{
"InstanceType": "${EMR_WORKER_INSTANCE_COUNT}",
"InstanceType": "${EMR_WORKER_INSTANCE_TYPE}",
"Market": "ON_DEMAND",
"InstanceRole": "CORE",
"Name": "core_instance_group"
}
],
"TerminationProtected": false,
"Ec2SubnetId": "${EMR_EC2_SUBNET}",
"Ec2KeyName": "${EMR_KEY_NAME}"
},
"BootstrapActions": [
{
"ScriptBootstrapAction": {
"Path":
"s3://support.elasticmapreduce/spark/maximize-spark-default-config"
},
"Name": "Maximize Spark Default Config"
},
{
"ScriptBootstrapAction": {
"Path":
"s3://emr-h2o-automl-benchmark/bootstrap-action-download-sparkling"
},
"Name": "Get Sparkling Water"
}
],
"ReleaseLabel": "emr-5.12.0",
"Steps": [
{
"HadoopJarStep": {
"Args": ["state-pusher-script"],
"Jar": "command-runner.jar"
},
"ActionOnFailure": "TERMINATE_CLUSTER",
"Name": "Setup Debugging"
}
],
"Applications": [
{
"Name": "Ganglia"
},
{
"Name": "Spark"
},
{
"Name": "Hadoop"
}
],
"Configurations": [
{
"Classification": "spark",
"Properties": {
"maximizeResourceAllocation": "true"
}
},
{
"Classification": "spark-defaults",
"Properties": {
"spark.dynamicAllocation.enabled": "false",
"spark.serializer":
"org.apache.spark.serializer.KryoSerializer",
"spark.scheduler.minRegisteredResourcesRatio": "1"
}
}
],
"ServiceRole": "EMR_DefaultRole",
"VisibleToAllUsers": true,
"Name": "Sparkling Water Test Cluster"
}
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 |
import json import string import boto3 ### Start config # Use these S3_BUCKET = 'emr-h2o-automl-benchmark' MODEL_SCRIPT_KEY = 'model_script.py' EMR_SPEC_KEY = 'emr-spec.json.template' # Possibly use these AWS_REGION = 'us-west-2' EMR_MASTER_INSTANCE_COUNT = 1 EMR_MASTER_INSTANCE_TYPE = 'm4.4xlarge' EMR_WORKER_INSTANCE_COUNT = 4 EMR_WORKER_INSTANCE_TYPE = 'r4.8xlarge' # Change these EMR_LOG_URI = 's3://emr-h2o-automl-benchmark/emr-logs/' EMR_KEY_NAME = 'emr_test_rsa' EMR_EC2_SUBNET = 'subnet-56c1661f' EMR_MASTER_SG = 'sg-1275526a' EMR_WORKER_SG = 'sg-1375526b' ### End config s3 = boto3.client('s3', region_name=AWS_REGION) emr = boto3.client('emr', region_name=AWS_REGION) def get_emr_spec(): tmp_key = '/tmp/' + EMR_SPEC_KEY s3.download_file(S3_BUCKET, EMR_SPEC_KEY, tmp_key) with open(tmp_key, 'r') as f: emr_spec_template = string.Template(f.read()) json_spec = emr_spec_template.substitute( dict( EMR_LOG_URI=EMR_LOG_URI, EMR_KEY_NAME=EMR_KEY_NAME, EMR_EC2_SUBNET=EMR_EC2_SUBNET, EMR_MASTER_SG=EMR_MASTER_SG, EMR_MASTER_INSTANCE_COUNT=EMR_MASTER_INSTANCE_COUNT, EMR_MASTER_INSTANCE_TYPE=EMR_MASTER_INSTANCE_TYPE, EMR_WORKER_SG=EMR_WORKER_SG, EMR_WORKER_INSTANCE_COUNT=EMR_WORKER_INSTANCE_COUNT, EMR_WORKER_INSTANCE_TYPE=EMR_WORKER_INSTANCE_TYPE)) emr_spec = json.loads(json_spec) return emr_spec def create_emr(): spec = get_emr_spec() resp = emr.run_job_flow(**spec) return resp['JobFlowId'] def get_spark_script_step(step_name, script_path): return { 'Name': step_name, 'ActionOnFailure': 'CANCEL_AND_WAIT', 'HadoopJarStep': { 'Jar': 'command-runner.jar', 'Args': ['aws', 's3', 'cp', script_path, '/home/hadoop/main.py'] } } def get_main_step(step_name, train_data_path, test_data_path, target_column, timeout): return { 'Name': step_name, 'ActionOnFailure': 'CANCEL_AND_WAIT', 'HadoopJarStep': { 'Jar': 'command-runner.jar', 'Args': [ 'spark-submit', '--deploy-mode', 'cluster', '--master', 'yarn', '--packages', 'ai.h2o:sparkling-water-core_2.11:2.2.10', '--conf', 'spark.yarn.maxAppAttempts=1', '/home/hadoop/main.py', train_data_path, test_data_path, target_column, timeout, ] } } def get_s3_copy_step(step_name, output_path): return { 'Name': step_name, 'ActionOnFailure': 'CANCEL_AND_WAIT', 'HadoopJarStep': { 'Jar': 'command-runner.jar', 'Args': ['s3-dist-cp', '--src', 'hdfs:///model', '--dest', output_path] } } def add_steps(cluster_id, steps): resp = emr.add_job_flow_steps(JobFlowId=cluster_id, Steps=steps) print(resp) def get_best_cluster(cluster_ids, pending_threshold): if not cluster_ids: return None cluster_info = [] for cluster_id in cluster_ids: pending_steps = emr.list_steps( ClusterId=cluster_id, StepStates=['PENDING'])['Steps'] cluster_info.append((cluster_id, len(pending_steps))) best_cluster_id, pending_count = min(cluster_info, key=lambda x: x[1]) print([best_cluster_id, pending_count]) return None if pending_count > pending_threshold else best_cluster_id def get_or_create_emr(): resp = emr.list_clusters(ClusterStates=['RUNNING', 'WAITING']) clusters = resp['Clusters'] print(clusters) cluster_ids = [ cluster['Id'] for cluster in clusters if cluster['Name'] == 'Sparkling Water Test Cluster' ] cluster_id = get_best_cluster(cluster_ids, pending_threshold=4) if cluster_id is None: cluster_id = create_emr() return cluster_id def run_job(timeout, train_data_path, test_data_path, output_path, target_column, script_path): cluster_id = get_or_create_emr() steps = [ get_spark_script_step('Get Spark Script', script_path), get_main_step('Run AutoML', train_data_path, test_data_path, target_column, timeout), get_s3_copy_step('Copy Model', output_path) ] add_steps(cluster_id, steps) def main(): timeout_seconds = '6000' train_file = 'train-10m' train_data_path = 's3://benchm-ml--main/{}.csv'.format(train_file) test_data_path = 's3://benchm-ml--main/test.csv' target_column = 'dep_delayed_15min' output_path = 's3://{}/output/test-{}-{}'.format( S3_BUCKET, timeout_seconds, train_file) script_path = 's3://{}/{}'.format(S3_BUCKET, MODEL_SCRIPT_KEY) run_job( timeout=timeout_seconds, train_data_path=train_data_path, test_data_path=test_data_path, output_path=output_path, target_column=target_column, script_path=script_path) if __name__ == '__main__': main() |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
from pyspark.sql import SparkSession import h2o from h2o.automl import H2OAutoML from pysparkling import * import traceback import timeit import sys spark = SparkSession.builder.appName('SparklingWaterApp').getOrCreate() spark_conf = spark.sparkContext.getConf().getAll() for item in spark_conf: print item hc = H2OContext.getOrCreate(spark) print hc print sys.argv if len(sys.argv) == 5 and all(x.startswith('s3://') for x in sys.argv[1:3]): s3_path_train = sys.argv[1] s3_path_test = sys.argv[2] target_column = sys.argv[3] timeout = int(sys.argv[4]) else: h2o.cluster().shutdown(prompt=False) spark.stop() raise Exception('Path in s3:// must be specified') print 'ATTEMPT DF LOAD' start_time = timeit.default_timer() train_df = spark.read.load( s3_path_train, format='com.databricks.spark.csv', header='true', delimiter=',', inferSchema='true') test_df = spark.read.load( s3_path_test, format='com.databricks.spark.csv', header='true', delimiter=',', inferSchema='true') elapsed = timeit.default_timer() - start_time print 'FINISH DF LOAD' print 'Time taken: %f seconds' % elapsed # H2O h2o_train_df = hc.as_h2o_frame(train_df) h2o_test_df = hc.as_h2o_frame(test_df) # Identify predictors and response x = h2o_train_df.columns y = target_column print h2o_train_df.types print h2o_test_df.types print 'ATTEMPT H2O MODEL BUILD' start_time = timeit.default_timer() # Transform all string columns to categoricals, or you could specify columns as in # https://github.com/h2oai/sparkling-water/blob/master/py/examples/scripts/ChicagoCrimeDemo.py for col in h2o_train_df.types: if h2o_train_df.types[col] == 'string': h2o_train_df[col] = h2o_train_df[col].asfactor() h2o_test_df[col] = h2o_test_df[col].asfactor() print h2o_train_df.types print h2o_test_df.types # For binary classification, response should be a factor h2o_train_df[y] = h2o_train_df[y].asfactor() h2o_test_df[y] = h2o_test_df[y].asfactor() aml = H2OAutoML(max_runtime_secs=timeout) aml.train(x=x, y=y, training_frame=h2o_train_df, leaderboard_frame=h2o_test_df) elapsed = timeit.default_timer() - start_time print 'FINISH H2O MODEL BUILD' print 'Time taken: %f seconds' % elapsed model_dir = 'hdfs:///model' model_path = h2o.save_model(model=aml.leader, path=model_dir, force=True) print model_path h2o.export_file( frame=aml.leaderboard, path=model_dir + '/leaderboard', force=True, parts=1) try: mojo_path = aml.leader.save_mojo(path=model_path + '.mojo', force=True) except Exception: print 'Export to MOJO not supported. Exception Handled:' print '------' traceback.print_exc() print '------' else: print mojo_path details_path = aml.leader.save_model_details( path=model_path + '_details', force=True) print details_path h2o.cluster().shutdown(prompt=False) spark.stop() |